|
|
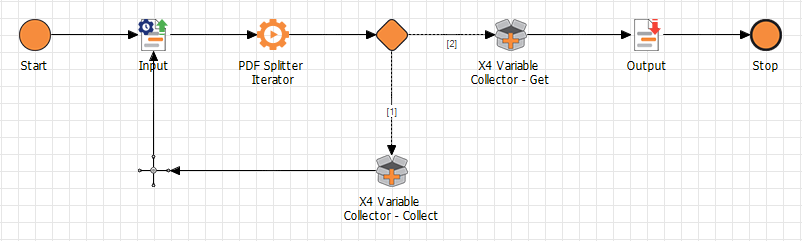
Dieser Adapter erwartet eine adapterspezifische Input-XML-Struktur, die den Pfad zum verarbeiteten PDF-Dokument im Repository enthält. Der Adapter gibt je Iteration die Daten eines PDF-Teildokuments als Binärdatenstrom oder als XML-Dokument aus.
Eigenschaften (Properties)
|
|
Bestimmt, welche Operation der Funktions-Adapter durchführt Mögliche Werte:
|
Parameter
|
|
Hauptklasse des Adapters (nicht verändern!) Mögliche Werte: |
|
|
Seitenzahl, von der gestartet werden soll Mögliche Werte: Beliebige positive ganze Zahl |
|
|
Schrittgröße, um die der Parameter Mögliche Werte: Beliebige positive ganze Zahl |
|
|
Anzahl der Seiten, die pro Iteration als separates PDF-Dokument ausgegeben werden sollen Mögliche Werte: Beliebige positive ganze Zahl |
|
|
PDF-Dokument Base64-kodiert in einem XML-Dokument ausgeben Mögliche Werte:
|
|
|
PDF-Dokument in mehreren Teilen in den Arbeitsspeicher laden (kann Performance-Verbesserungen bringen) Mögliche Werte:
|
Statuswerte
|
|
Die Operation wurde erfolgreich ausgeführt. |
|
|
Die Operation wurde erfolgreich ausgeführt, jedoch ohne Ergebnis. |
|
|
Die Operation ist aufgrund eines technischen Fehlers fehlgeschlagen. |
Input
Dieser Funktions-Adapter erwartet eine adapterspezifische Input-XML-Struktur, die den Pfad zum verarbeiteten PDF-Dokument im Repository oder die Base64-Zeichenkette enthält.
PDF im PDF-Format
Folgendes Input-XML-Dokument enthält den Pfad zu einem PDF-Dokument im Repository.
<?xml version="1.0" encoding="UTF-8"?>
<PDF url="xstore://Project/Folder/Input.pdf"/>
PDF im Base64-Format
Folgendes Input-XML-Dokument enthält die Base64-Zeichenkette.
<?xml version="1.0" encoding="UTF-8"?>
<PDF encoding="base64">
Base64-Zeichenkette
</PDF>
Output
Wenn der Parameter ToXML deaktiviert ist, kann der Output direkt als Buffer-Datei im PDF-Format gespeichert werden.
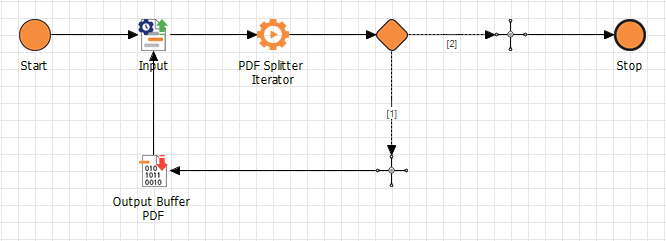
Wenn der Parameter ToXML aktiviert ist, sieht der Output wie folgt aus:
<?xml version="1.0" encoding="UTF-8"?>
<PDF encoding="base64">
Base64-Zeichenkette
</PDF>
Beispiel
Der Prozess teilt die XML auf und speichert alle Zwischenergebnisse im XML-Format in einer Variablen. Um die Variablen zu speichern, wird der Adapter X4 Variable Collector verwendet.