PDF Splitter Iterator
 | PDF Splitter Iterator: Splits an unprotected PDF document into several new PDF documents. |
This adapter expects an adapter-specific input XML structure which contains the path to the processed PDF document in the repository. The adapter outputs the data of a PDF part document as a binary data stream or as an XML document per iteration.
Properties
Operation | Determines which operation the adapter executes Possible values:
|
Parameter
Adapter | Main class of the adapter (do not change!) Possible values: |
Start | Page number from which to start Possible values: Any positive integer |
Step | Step size by which the Possible values: Any positive integer |
Count | Number of pages to be output as a separate PDF document per iteration. Possible values: Any positive integer |
toXML | Output PDF document Base64-encoded in an XML document Possible values:
|
ReadPartially | Load PDF document into memory in multiple parts (can improve the performance) Possible values:
|
Status values
1 | The operation was executed successfully. |
0 | The operation was executed successfully, but without any result. |
-1 | The operation failed due to a technical error. |
Input
This function adapter expects an adapter-specific input XML structure which contains the path to the processed PDF document in the repository or the Base64 string.
PDF in PDF format
The following input XML document contains the path to a PDF document in the repository.
<?xml version="1.0" encoding="UTF-8"?>
<PDF url="xstore://Project/Folder/Input.pdf"/>PDF in Base64 format
The following input XML document contains the Base64 string.
<?xml version="1.0" encoding="UTF-8"?>
<PDF encoding="base64">
Base64 string
</PDF>Output
If the ToXML parameter is disabled, the output can be saved directly as a buffer file in PDF format.
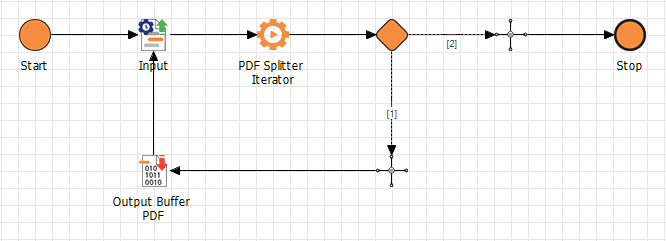
If the ToXML parameter is enabled, the output looks like this:
<?xml version="1.0" encoding="UTF-8"?>
<PDF encoding="base64">
Base64 string
</PDF>Example
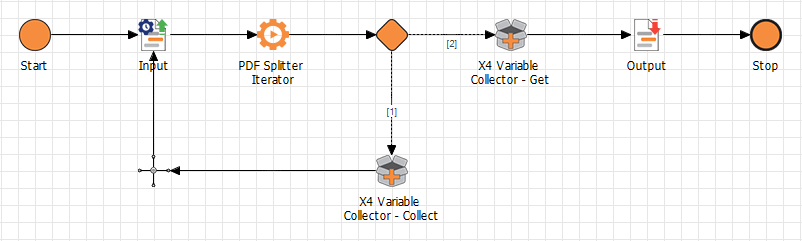
The process splits the XML and stores all intermediate results in XML format in a variable. To store the variables, the X4 Variable Collector adapter is used.